
一、函数介绍
REGEX 函数是指支持正则表达式的系列函数,包含 REGEXMATCH、REGEXEXTRACT 以及 REGEXREPLACE 函数,让你可以方便地在海量文本中批量查找、提取或替换你想要的模式化内容。
二、函数解读
REGEXMATCH
- 公式功能:判断文本是否包含正则表达式所描述的内容,判断结果显示为布尔值 TRUE 或 FALSE
- 函数公式: = REGEXMATCH(文本, 正则表达式)
- 参数释义:
- 文本(必填):用于匹配正则表达式的文本内容
- 正则表达式(必填) :用于检验文本的正则表达式
- 举个例子: = REGEXMATCH("Sheets", "S.e") 将返回结果 TRUE
REGEXEXTRACT
- 公式功能:提取文本中符合正则表达式的内容
- 函数公式: = REGEXEXTRACT(文本, 正则表达式)
- 参数释义:
- 文本(必填):用于匹配正则表达式的文本
- 正则表达式(必填) :需要被提取内容的正则表达式
- 举个例子: =REGEXEXTRACT("abcedfg", "c.*f") 用于提取 abcedfg c-f(含c、f)之间的所有文本将返回结果 cedf
REGEXREPLACE
- 公式功能:将文本中符合正则表达式的内容替换成指定内容
- 函数公式: REGEXREPLACE(文本, 正则表达式, 替换内容)
- 参数释义:
- 文本(必填):用于匹配正则表达式并替换内容的文本
- 正则表达式(必填) :需要被替换内容的正则表达式
- 替换内容(必填):想要替换的指定内容
- 举个例子: =REGEXREPLACE("abcedfg", "a.*d", "xyz") 将返回结果 xyzfg
三、正则表达式语法
作为该系列函数的核心,正则表达式可以用于检查字符串中是否包含符合指定规则的内容。
1.举例
假设你需要从一大堆文字材料里提取邮箱地址。你肯定知道邮箱地址的特征,但这种规则确定,文本长度和内容不确定的东西,用正则怎么去表示呢?如下:
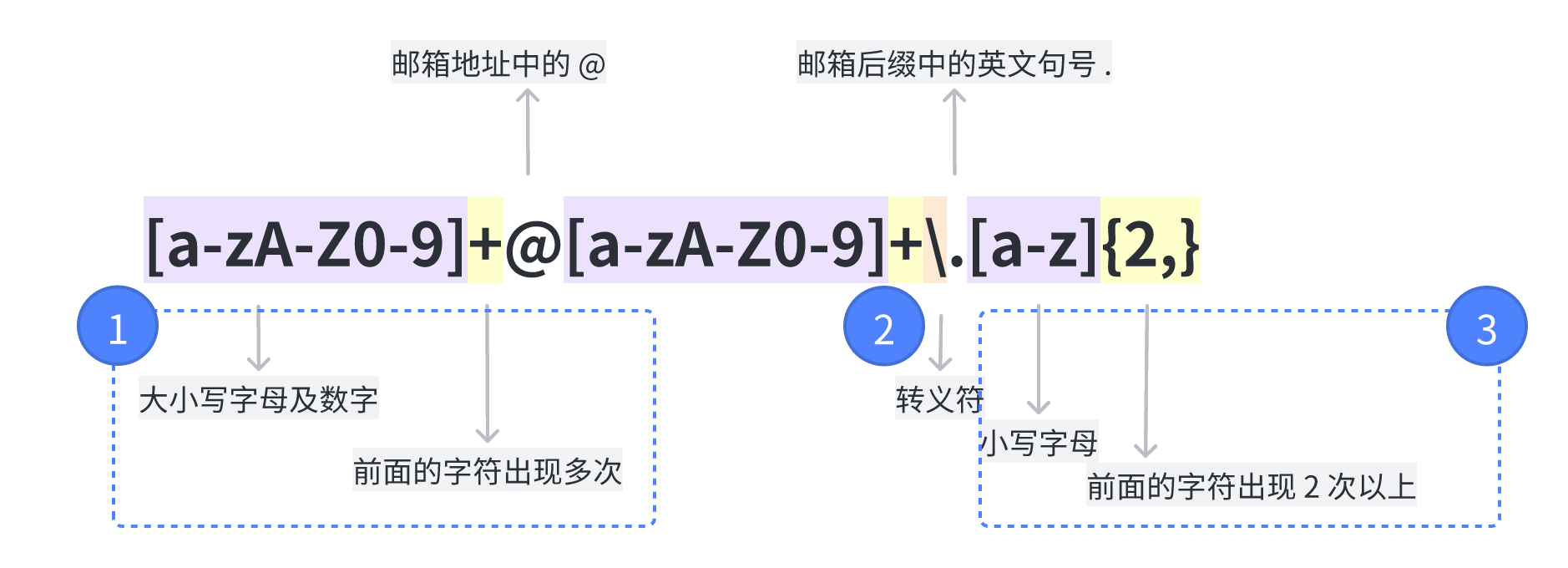
250px|700px|reset
别被这些字符吓到,你可以在本文“元字符”部分了解其准确含义,而在上述例子中,它的意思是:
- 第 1 部分:匹配的是邮箱前缀的特征:一串字母或数字的组合,字符长度不确定(用 + 号表示)—— 这一条规则同样也适用于邮箱后缀的前半部分,所以 @ 之后又写了一遍
- 第 2 部分:匹配的是邮箱后缀中 example.com 里的英文句号 . 部分 —— 由于 . 在正则语法中有特殊含义,不能像前面的 @ 一样直接匹配,所以前面用转义符 \ 来表示严格匹配句号本身
- 第 3 部分:匹配的是邮箱后缀的后半部分:两个及以上小写字母组成的内容 —— 也就是邮箱域名中常见的 example.com、example.cn 中的 com、cn 部分
注意,就像解数学题有不同的解法,对同一类型内容的正则表达式也可能不同,以上仅是邮箱正则表达式的一个参考,下面进入语法规则详解:
2.精确匹配
如果不使用特殊的元字符,你可以像平时检索任何内容一样,直接指定精确检索的内容。比如 = REGEXMATCH("Sheets", "se") 表示在 Sheets 中直接匹配 se —— 匹配不到,结果是 FALSE。
3.元字符
正则表达式更多依赖于元字符 —— 元字符并不表达它的字面意思,而是代表特殊含义。在上面例子中,如果将匹配的正则表达式修改为 S.e,也就是公式改成 = REGEXMATCH("Sheets", "S.e"),会得到 TRUE 的结果。因为 . 是一个元字符,可以用来表示任何非换行符的单个字符,所以 S.e 会匹配到 Sheets 中的 She 部分。
匹配规则:默认从左至右,如果不指定重复次数的话,会返回满足正则表达式的第一组值
4. 前后预查
前后预查,也叫断言、环视(look-around),用于判断字符串前后是否满足一定正则条件。它并不捕获文本,只用于辅助判断,并返回匹配条件的结果。预查的条件需要写在小括号中,目前支持以下 2 种方式:
5.分组与捕获 (小括号的用法)
用小括号括起来部分就是一个分组。分组又包含捕获组和非捕获组,这是什么意思呢?
- 捕获组(Capturing Groups)该组用于匹配并获取括号中的结果
- 非捕获组(Non-capturing Groups)该组仅用于匹配但不获取其结果,也无法用于后续的二次计算
关于分组,有一些实用窍门:
- 多个分组:
使用 REGEXEXTRACT 提取内容时,可通过多个分组一次提取多列内容。如下方这样,通过 3 个括号,将内容平分在了 3 列中。
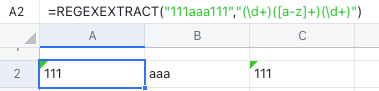
250px|700px|reset
此外,分组是可以嵌套使用的,如下方这样,多层嵌套后,就能一次拆分为 4 列:
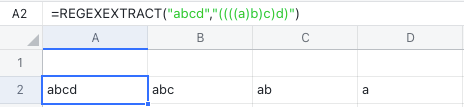
250px|700px|reset
- 反向引用:
在分组后写 \n (n 是一个正整数),表示引用这个分组内的值,因此你可以用 (.)\1 来匹配两个连续的重复字符。