
- 関数の説明
REGEXMATCH ・ REGEXEXTRACT ・ REGEXREPLACE 関数は、正規表現を使用して、データ内のテキストを検索、抽出、または置換します。
- 関数の書式
REGEXMATCH
- 機能 :指定したテキストに正規表現とマッチする内容が含まれているかどうかを判断し、返り値としてブール値 TRUE または FALSE を返します。
- 書式 := REGEXMATCH(テキスト, 正規表現)
- 引数 :
- テキスト(必須) :正規表現とマッチする内容が含まれているかどうか判断するテキスト。
- 正規表現(必填) :テキストに適用する正規表現。
- 使用例 := REGEXMATCH("Sheets", "S.e") の返り値は、TRUE となります。
REGEXEXTRACT
- 機能 :テキストに含まれている正規表現とマッチする内容を抽出します。
- 書式 := REGEXEXTRACT(テキスト, 正規表現)
- 引数 :
- テキスト(必須) :正規表現とマッチする内容を抽出するテキスト。
- 正規表現(必須) :抽出される内容にマッチする正規表現。
- 使用例 :=REGEXEXTRACT("abcdefg", "c.*f") の返り値は、"abcdefg" の c から f までの文字列(c と f を含む)" cdef " となります。
REGEXREPLACE
- 機能 :テキストに含まれている正規表現とマッチする内容を置換します。
- 書式 :REGEXREPLACE(テキスト, 正規表現, 置換内容)
- 引数 :
- テキスト(必須) :正規表現とマッチする内容を置換するテキスト。
- 正規表現(必須) :置換される内容にマッチする正規表現。
- 置換内容(必填) :置換後の内容。
- 使用例 :=REGEXREPLACE("abcdefg", "a.*d", "xyz") の返り値は、" xyzefg " となります。
- 正規表現の書き方
この関数シリーズを活用するポイントは、正規表現を使ってルールを指定し、指定したルールを満たす内容が文字列に含まれているかどうかチェックすることです。
3.1 使用例
大量のテキストからメールアドレスを抽出したいとします。メールアドレスの特徴は分かっています。しかし、この種の書き方にはルールがあるものの、長さや内容は決まっていない文字列を正規表現でどのように表せるのでしょうか?以下の例をご覧ください。
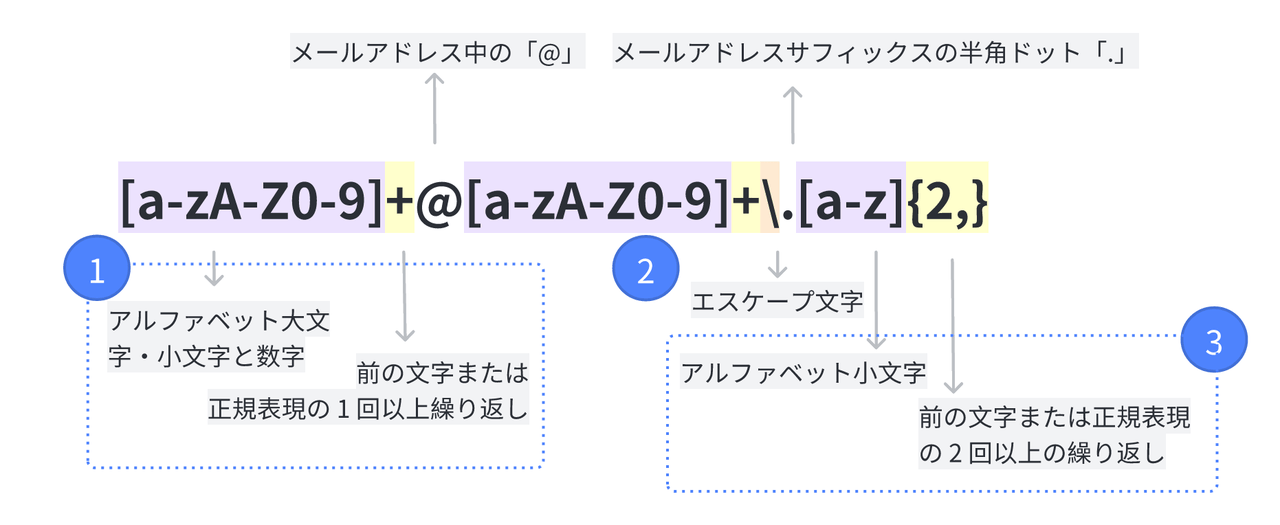
250px|700px|reset
たくさんの記号に圧倒されないでください。本記事の 「メタ文字」 で、それぞれの正確な意味を理解できます。上記の正規表現は、以下の意味となります。
- 第 1 の部分 :メールアドレスの前半、つまりアルファベットまたは数字を組み合わせた部分にマッチします。文字列の長さは不確定( + 記号で表現)です。同じ正規表現をメールアドレスの後半、つまり @ 以降にも使います。
- 第 2 の部分 :メールアドレスの後半にあるドメイン名 example.com に含まれる 半角ドット . にマッチします。正規表現において半角ドット . は特別な意味を持っていて、@ のように直接指定できないため、前にエスケープ記号の \ を付ける必要があります。
- 第 3 の部分: 2 文字以上のアルファベット小文字で書かれた文字列、つまりメールアドレスのドメイン名によくある example.com や example.cn 中の com と cn の部分にマッチします。
数学の問題に異なる解法があるのと同じように、同じ内容にマッチする正規表現にもさまざまな書き方があります。上記は一例に過ぎません。これから詳しい書き方を紹介します。
3.2 通常の文字
特殊な正規表現を使わないなら、通常の検索時と同じように、マッチさせたい内容をそのまま指定します。例えば、= REGEXMATCH("Sheets", "se") は、文字列 "Sheets" 中で "se" という文字列にマッチする内容があるかどうかを探します。この場合は見つからないので、返り値は FALSE となります。
3.3 メタ文字
正規表現の大部分は、特殊な意味を持つ「メタ文字」を使って書きます。たとえば、さきほどの例で正規表現を「 S.e 」と書き換えて、= REGEXMATCH("Sheets", "S.e") とすると、返り値は TRUE となります。なぜなら、半角ドット「.」はメタ文字の一つで、改行文字以外の 1 文字を表すからです。そのため、「 S.e 」という正規表現は、" Sheets " 中の " She " の部分にマッチします。
マッチルール :与えられたテキストをデフォルトでは左から右にチェックし、繰り返し回数が指定されていない場合、マッチする最初の正規表現の値を返します。
3.4 先読みと後読み(ルックアラウンド)
先読みと後読みは、ルックアラウンド(look-around)とも呼ばれ、文字列の前後が正規表現にマッチするかどうかを判断したい場合に使います。テキストをキャプチャするのではなく、補助的な判断に使うもので、マッチ条件の結果を返します。先読みのマッチ条件は丸括弧で囲みます。現在のところ、以下の 2 つの書き方をサポートしています。
3.5 グループとキャプチャ(丸括弧の使い方)
丸括弧で囲んだ部分はグループとなります。グループにはキャプチャグループと非キャプチャグループがあり、以下の違いがあります。
- キャプチャグループ(Capturing Groups) は、丸括弧内の正規表現にマッチした結果を取得するのに使います。
- 非キャプチャグループ(Non-capturing Groups) は、丸括弧内の正規表現をマッチのみに使い、その結果を取得しません。あとでマッチした内容を使うこともできません。
グループに関する実用的なテクニックには、以下のものがあります。
- 複数のグループ:
REGEXEXTRACT 関数で抽出を行うとき、複数のグループを使うと、 一回の呼び出しで複数の列にまたがる内容を抽出 できます。以下の例では、3 つの括弧を使って、指定したテキストを 3 つの列に分けて抽出しています。
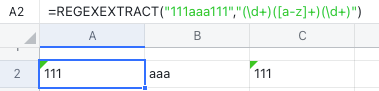
250px|700px|reset
また、グループをネストして使うこともできます。以下の例では、グループを複数回ネストして、一回の呼び出しで 4 つの列に分けた抽出を行っています。
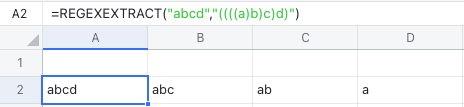
250px|700px|reset
- 後方参照:
グループのあとに「 \n 」(n は正の整数)と書くと、指定したグループの値を参照できます。そのため、「 (.)\1 」という正規表現を使うと、同じ文字 2 個の繰り返しにマッチします。